Параллельные вычисления на Python#
Данный раздел был подготовлен совместно со студентом ТвГУ Луковниковым Д.И.
Параллельные вычисления, или параллельная обработка, представляют собой использование нескольких или многих вычислительных устройств для одновременного выполнения разных частей одной программы или проекта. Они позволяют ускорить выполнение задач и повысить эффективность работы программ. Параллельные вычисления очень полезны при математических, физических и любых других расчётах или действий, они позволяют ускорить выполнение задач путем одновременного выполнения нескольких процессов.
Библиотеки для распараллеливания на языке программирования Python#
Библиотека joblib#
Эта библиотека позволяет распараллеливать выполнение функций и методов в программах. Это может значительно ускорить обработку данных и выполнение других тяжеловесных задач. Кроме того, Joblib позволяет увеличить производительность научных вычислений, используя функции и методы из различных модулей библиотеки SciPy, NumPy итд., которые могут использовать возможности Joblib для распараллеливания выполнения некоторых операций. Это позволяет значительно ускорить обработку больших объемов данных в рамках научных исследований и других задач научных вычислений.
Одним из главных преимуществ Joblib является возможность сохранения и загрузки выходных данных, что позволяет избежать повторных вычислений и повысить эффективность работы. Это особенно важно для научных экспериментов, где результаты должны быть воспроизводимы, так как Joblib обеспечивает прозрачное распределение задач между ядрами процессора и автоматическое кэширование результатов выполнения функций.
С помощью joblib можно узнать, сколько CPU-ядер/потоков мы можем использовать у нашего процессора. Для этого нужно импортировать библиотеку joblib и вызвать метод
import joblib
print(f"Number of cpu: {joblib.cpu_count()}")
Number of cpu: 80
В результате мы увидим количество возможно используемых логических ядер процессора.
Рассмотрим задачу, где нам нужно перемножить матрицы AxB. Реализуем её на языке программирования Python с использованием библиотеки joblib. Для этого нам нужно импортировать функцию Parallel из библиотеки joblib, которая используется для создания нескольких потоков, которые могут выполнять задачи параллельно. По умолчанию количество потоков равно числу ядер процессора. Так же мы можем передать -1 для использования всех ядер. Функция delayed используется для отсрочки выполнения кода. Она используется для того, чтобы joblib создал список вызова функций, которые нужно выполнить параллельно. Этот список затем передается в функцию Parallel, которая занимается параллельным выполнением задач. Так же зафиксируем время выполнения программы припомощи модуля time
import numpy as np
import time
import matplotlib.pyplot as plt
from joblib import Parallel, delayed
Задаем две матрицы А и В, указываем их размерности и заполняем генератором случайных чисел в интервале от 0 до 10
A = np.random.randint(0,high=10,size=(6000,1000))
B = np.random.randint(0,high=10,size=(1000,6000))
Для перемножения матриц воспользуемся методом numpy.dot и сделаем замер времени выполнения
start_single=time.time()
res_single = np.dot(A,B)
end_single=time.time()
time_single=end_single-start_single
print('Время однопоточного выполнения:',time_single)
Время однопоточного выполнения: 53.12894892692566
Добавим функцию для распараллеливания метода np.dot
Эта функция распределяет вычисления между несколькими процессами. Стратегия, применяемая для распространения данных, очень проста. Каждый процесс имеет полную матрицу B и непрерывный блок строк A, поэтому он может вычислить блок строк AxB. В конце концов, результат каждого процесса суммируется для построения результирующей матрицы.
def parallel_dot(A,B,n_jobs):
"""
Вычисляет A x B, используя больше процессов.
Это работает только тогда, когда число
строк A и n_jobs четные.
"""
parallelizer = Parallel(n_jobs=n_jobs)
# this iterator returns the functions to execute for each task
tasks_iterator = ( delayed(np.dot)(A_block,B)
for A_block in np.split(A,n_jobs) )
result = parallelizer( tasks_iterator )
# merging the output of the jobs
return np.vstack(result)
Добавим функцию jl_run для удобного запуска на разном количестве потоков и добавим туда подсчет времени затраченого на выполнение
def jl_run(thr):
start_parallel=time.time()
res_jl = parallel_dot(A,B,thr)
end_parallel=time.time()
time_jl=end_parallel-start_parallel
return time_jl,res_jl
Выведем время затраченое на многопоточное выполнение функции и посчитаем фактор ускорения
time_jl,res_jl=jl_run(8)
print('Время многопоточного выполнения (JobLib):',time_jl)
Время многопоточного выполнения (JobLib): 13.18322467803955
print ('Ускорение в: ',time_single/time_jl,'раз(а)')
Ускорение в: 4.030041983235497 раз(а)
Сравним результаты однопоточного перемножения матрииц и многопоточного
res_jl
array([[21762, 21117, 20924, ..., 21123, 21773, 19821],
[21125, 20522, 20289, ..., 21082, 21474, 19998],
[20733, 20891, 20093, ..., 20778, 21192, 19740],
...,
[21226, 20899, 20954, ..., 21438, 21102, 20061],
[21354, 20991, 20751, ..., 20524, 21446, 19886],
[19744, 20011, 19658, ..., 20060, 20305, 19120]])
res_single
array([[21762, 21117, 20924, ..., 21123, 21773, 19821],
[21125, 20522, 20289, ..., 21082, 21474, 19998],
[20733, 20891, 20093, ..., 20778, 21192, 19740],
...,
[21226, 20899, 20954, ..., 21438, 21102, 20061],
[21354, 20991, 20751, ..., 20524, 21446, 19886],
[19744, 20011, 19658, ..., 20060, 20305, 19120]])
Воспользуемся функцией numpy.array_equal для проверки результатов
np.array_equal (res_jl,res_single)
True
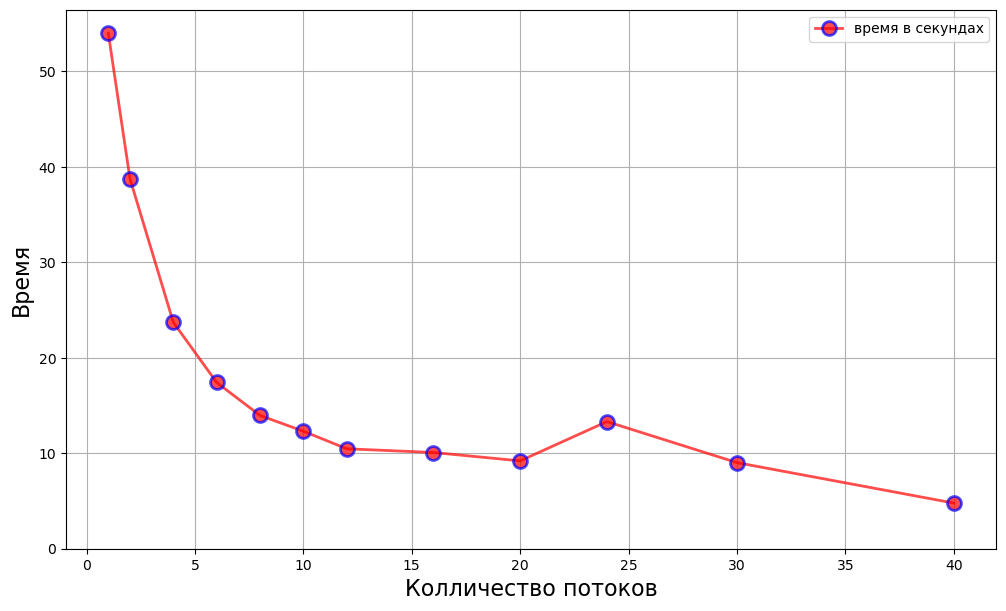
Построим график зависимости времени выполнения алгоритма от количества потоков (от 1 до 40)
y_speedup=[]
threads=[1,2,4,6,8,10,12,16,20,24,30,40]
for x in threads:
time_jl,res_jl=jl_run(x)
y_speedup.append(time_jl)
plt.figure(figsize=(12, 7))
plt.plot(threads, y_speedup, 'o-r', alpha=0.7, label="время в секундах", lw=2, mec='b', mew=2, ms=10)
plt.legend()
plt.xlabel('Колличество потоков', size=16)
plt.yticks(np.arange(0, max(y_speedup)*1.1, 10))
plt.ylabel('Время', size=16)
plt.grid(True)
Библиотека multiprocessing#
Библиотека multiprocessing языка программирования Python является стандартной библиотекой, которая предоставляет инструменты для создания и управления процессами в операционной системе. Она позволяет распараллеливать выполнение задач путем создания нескольких процессов и использования их для одновременной обработки данных.
Основными компонентами библиотеки multiprocessing являются классы Process и Pool. Класс Process представляет один процесс, который может быть запущен и выполнен независимо от других процессов. Класс Pool представляет пул процессов, который позволяет распределять задачи между несколькими процессами.
Кроме того, библиотека multiprocessing предоставляет механизмы для обмена сообщениями между процессами. Это позволяет процессам обмениваться информацией и синхронизировать свою работу, что может быть полезно для решения определенных задач.
С помощью multiprocessing также можно узнать, сколько CPU-ядер/потоков мы можем использовать у нашего процессора. Для этого нужно импортировать библиотеку multiprocessing и вызвать метод
import multiprocessing
max_threads = multiprocessing.cpu_count()
print("Number of cpu:", max_threads)
Number of cpu: 80
Аналогично как в предущих примерах для перемножения матриц мы будем использовать метод np.dot, определим функцию для перемножения матриц matrix_multiply и функцию mp_run для удобного запуска на разном количестве потоков и добавим туда подсчет времени на выполнение.
Нам так же требуется разбить начальные матрицы на равные части для одновременного параллельного запуска.
В конце суммиируем результаты для полученния результирующей матрицы.
import numpy as np
from multiprocessing import Pool
# Define the matrix multiplication function
def matrix_multiply(args):
A, B = args
return np.dot(A, B)
def mp_run(thr):
start=time.time()
# Split the matrices into N parts
A_parts = np.array_split(A, thr, axis=1)
B_parts = np.array_split(B, thr)
# Create a multiprocessing pool with N workers
pool = Pool(thr)
# Map the matrix multiplication function to the N parts of the matrices
C_parts = pool.map(matrix_multiply,
[(A_part, B_part) for A_part, B_part in zip(A_parts, B_parts)])
pool.close()
end=time.time()
# Sum the parts of the result matrix
result_mp = np.sum(C_parts, axis=0)
return end-start,result_mp
Запускаем перемножение матриц A и В на 8 потоках и вычисляем фактор ускорения
time_mp,result_mp=mp_run(8)
result_mp
array([[21762, 21117, 20924, ..., 21123, 21773, 19821],
[21125, 20522, 20289, ..., 21082, 21474, 19998],
[20733, 20891, 20093, ..., 20778, 21192, 19740],
...,
[21226, 20899, 20954, ..., 21438, 21102, 20061],
[21354, 20991, 20751, ..., 20524, 21446, 19886],
[19744, 20011, 19658, ..., 20060, 20305, 19120]])
print('Время многопоточного выполнения (multiprocessing):',time_mp)
Время многопоточного выполнения (multiprocessing): 8.661626815795898
print ('Ускорение в: ',time_single/time_mp,'раз(а)')
Ускорение в: 6.133830290406451 раз(а)
Проверяем что результаты перемножения совпадают
np.array_equal (result_mp,res_single)
True
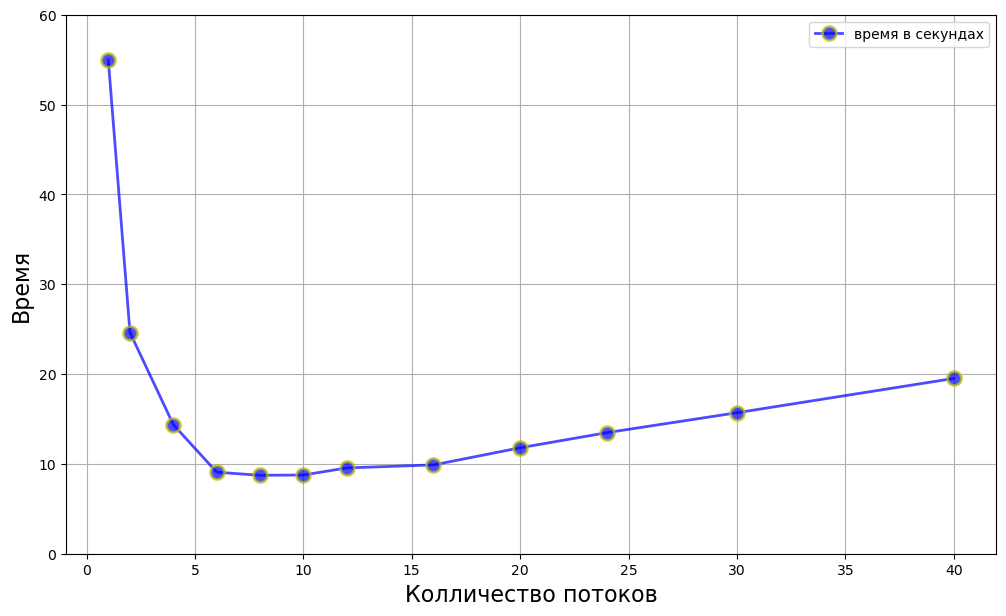
Построим график зависимости времени выполнения алгоритма от количества потоков (от 1 до 40)
y_speedup_mp=[]
threads=[1,2,4,6,8,10,12,16,20,24,30,40]
for x in threads:
time_mp,res_mp=mp_run(x)
y_speedup_mp.append(time_mp)
plt.figure(figsize=(12, 7))
plt.plot(threads, y_speedup_mp, 'o-b', alpha=0.7, label="время в секундах", lw=2, mec='y', mew=2, ms=10)
plt.legend()
plt.xlabel('Колличество потоков', size=16)
plt.yticks(np.arange(0, max(y_speedup_mp)*1.1, 10))
plt.ylabel('Время', size=16)
plt.grid(True)
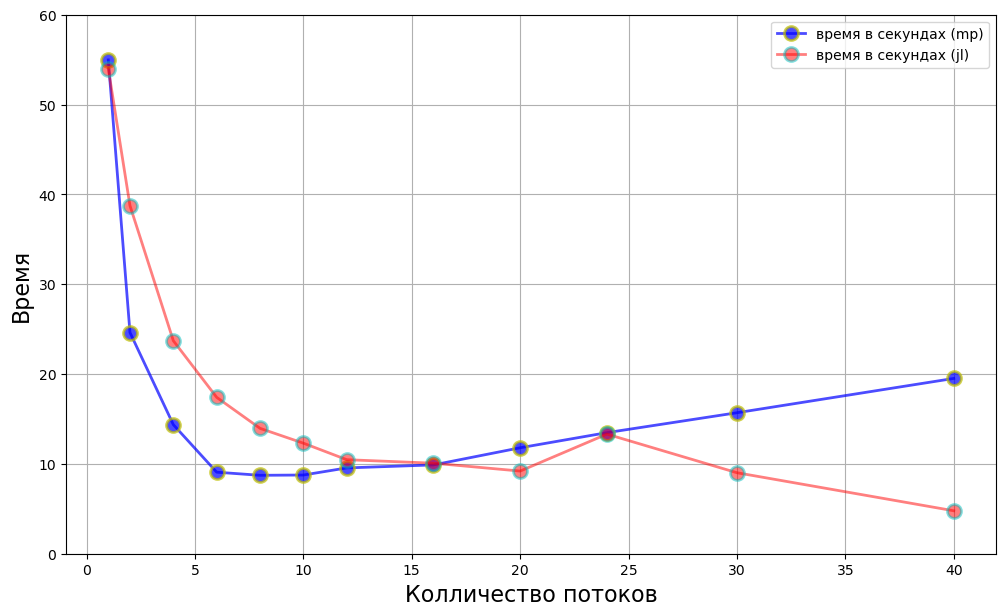
Сравним эффективность использованиия Joblib и Multiprocessing
plt.figure(figsize=(12, 7))
plt.plot(threads, y_speedup_mp, 'o-b', alpha=0.7, label="время в секундах (mp)", lw=2, mec='y', mew=2, ms=10)
plt.plot(threads, y_speedup, 'o-r', alpha=0.5, label="время в секундах (jl)", lw=2, mec='c', mew=2, ms=10)
plt.legend()
plt.xlabel('Колличество потоков', size=16)
plt.yticks(np.arange(0, max(y_speedup_mp)*1.1, 10))
plt.ylabel('Время', size=16)
plt.grid(True)